

Reliant 的论文搜索 AI 承担了科学界的数据处理工作
事实证明,人工智能模型能够完成很多事情,但我们真正想让它们完成什么任务呢?最好是单调乏味的工作——研究和学术界有很多这样的工作。Reliant希望专注于那种耗时的数据提取工作,而这种工作目前是疲惫的研究生和实习生的专长。
首席执行官 Karl Moritz 表示:“人工智能能做的最好的事情就是改善人类体验:减少琐碎劳动,让人们做对他们来说重要的事情。”在研究领域,他和联合创始人 Marc Bellemare 和 Richard Schlegel 已经工作多年,文献综述是这种“琐碎劳动”最常见的例子之一。
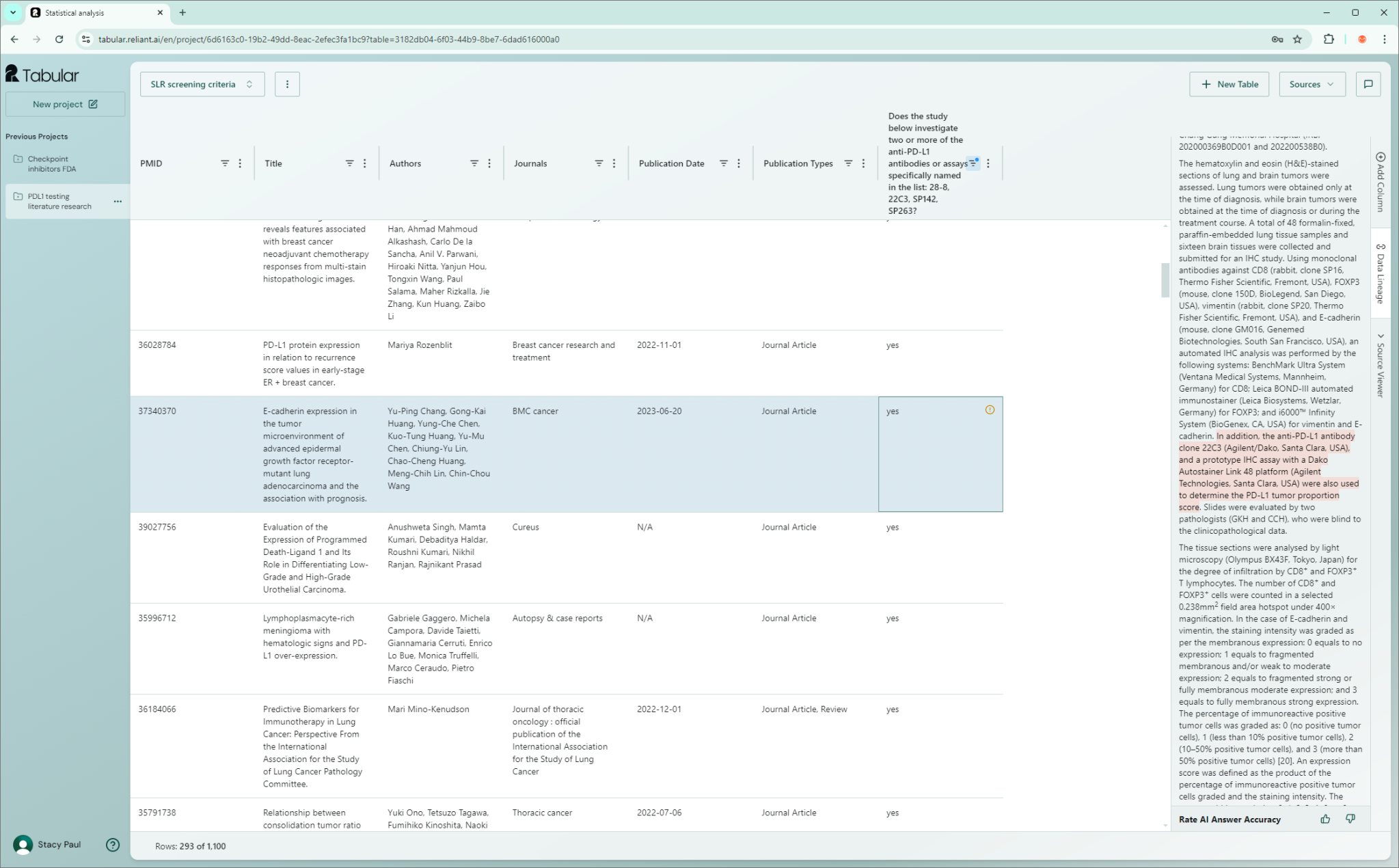
每篇论文都会引用先前和相关的研究成果,但在科学的海洋中找到这些来源并不容易。有些论文,如系统评价,引用或使用的数据来自数千篇论文。
对于一项研究,莫里茨回忆道:“作者必须查阅 3,500 份科学出版物,其中很多最终都变得不相关。提取少量有用信息需要花费大量时间——这感觉真的应该由人工智能自动完成。”
他们知道现代语言模型可以做到这一点:一项实验让 ChatGPT 执行这项任务,发现它能够以 11% 的错误率提取数据。就像法学硕士可以做的许多事情一样,这令人印象深刻,但与人们的实际需要完全不同。

Reliant 的论文搜索 AI 承担了科学界的数据处理工作
“这还不够好,”莫里茨说。“对于这些知识任务,尽管它们可能很琐碎,但重要的是不要犯错误。”
Reliant 的核心产品 Tabular 部分基于 LLM(LLaMa 3.1),但增加了其他专有技术,效率更高。他们表示,在上述数千项研究的提取中,Tabular 完成了同样的任务,并且没有出现任何错误。
这意味着:你输入一千份文件,假设你想从中得到这个、那个和其他数据,Reliant 会仔细检查这些文件并找到这些信息 — — 无论这些信息是否标记和结构完美,或者(更有可能)是否不完美。然后它会将所有数据和你想要的分析弹出到一个漂亮的 UI 中,这样你就可以深入研究个别案例。
“我们的用户需要能够同时处理所有数据,我们正在构建一些功能以允许他们编辑现有的数据,或者从数据转到文献;我们认为我们的职责是帮助用户找到需要关注的地方,”莫里茨说。
Reliant 的论文搜索 AI 承担了科学界的数据处理工作
这种量身定制且有效的人工智能应用——不像数字朋友那样引人注目,但几乎肯定更具可行性——可以加速许多高技术领域的科学发展。投资者注意到了这一点,并提供了 1130 万美元的种子轮融资;Tola Capital 和 Inovia Capital 领投,天使投资者 Mike Volpi 参与其中。
与任何 AI 应用一样,Reliant 的技术非常依赖计算,这就是为什么该公司购买了自己的硬件,而不是从大型供应商那里租用硬件。在公司内部使用硬件既有风险也有回报:你必须让这些昂贵的机器收回成本,但你有机会利用专用计算来解决问题。
“我们发现,如果时间有限,那么给出好的答案是非常困难的,”莫里茨解释道——例如,如果一位科学家要求系统对一百篇论文进行一项新颖的提取或分析任务。除非他们预测用户可能会问什么,并提前找出答案或类似的东西,否则它可以很快完成,也可以做得很好,但不能两者兼得。
“问题是,很多人都有同样的问题,所以我们可以在他们提出问题之前找到答案,以此作为起点,”这家初创公司的首席科学官贝勒马尔说。“我们可以将 100 页的文本提炼成其他内容,这可能不是你想要的,但对我们来说更容易处理。”
想想看:如果你要从一千本小说中提取含义,你会等到有人询问人物的名字后再去获取吗?还是你会提前做这项工作(以及地点、日期、关系等),因为你知道这些数据很可能会需要?当然是后者——如果你有足够的计算能力的话。
这种预先提取还使模型有时间解决不同科学领域中不可避免的歧义和假设。当一个指标“指示”另一个指标时,它在制药领域和病理学或临床试验中的含义可能不同。不仅如此,语言模型往往会根据被问到某些问题的方式给出不同的输出。因此,Reliant 的工作就是将歧义转化为确定性——“只有你愿意在某一科学或领域投资,你才能做到这一点,”Moritz 指出。
作为一家公司,Reliant 的首要重点是确定该技术能够自给自足,然后再尝试任何更雄心勃勃的事情。“为了取得有趣的进展,你必须有一个远大的愿景,但你也需要从具体的事情开始,”Moritz 说。“从初创企业生存的角度来看,我们专注于营利性公司,因为他们给我们钱来支付我们的 GPU。我们不会亏本卖给客户。”
人们可能认为该公司会感受到来自 OpenAI 和 Anthropic 等公司的压力,这些公司正在投入大量资金来处理数据库管理和编码等更结构化的任务,或者来自 Cohere 和 Scale 等实施合作伙伴的压力。但 Bellemare 很乐观:“我们正在顺应民意构建这个平台——我们的技术堆栈的任何改进对我们来说都是有益的。LLM 可能是其中八个大型机器学习模型之一——其他模型完全属于我们专有,从头开始根据我们的数据专有性进行构建。”
生物科技和研究行业向人工智能驱动的转型当然才刚刚开始,未来几年可能还很不顺利。但 Reliant 似乎已经找到了坚实的基础。
“如果你想要 95% 的解决方案,并且偶尔向你的一位客户道歉,那很好,”莫里茨说。“我们关注的是准确率和召回率,以及错误率。坦率地说,这就足够了,我们很乐意把剩下的留给别人。”
相关文章





